October 20, 2017
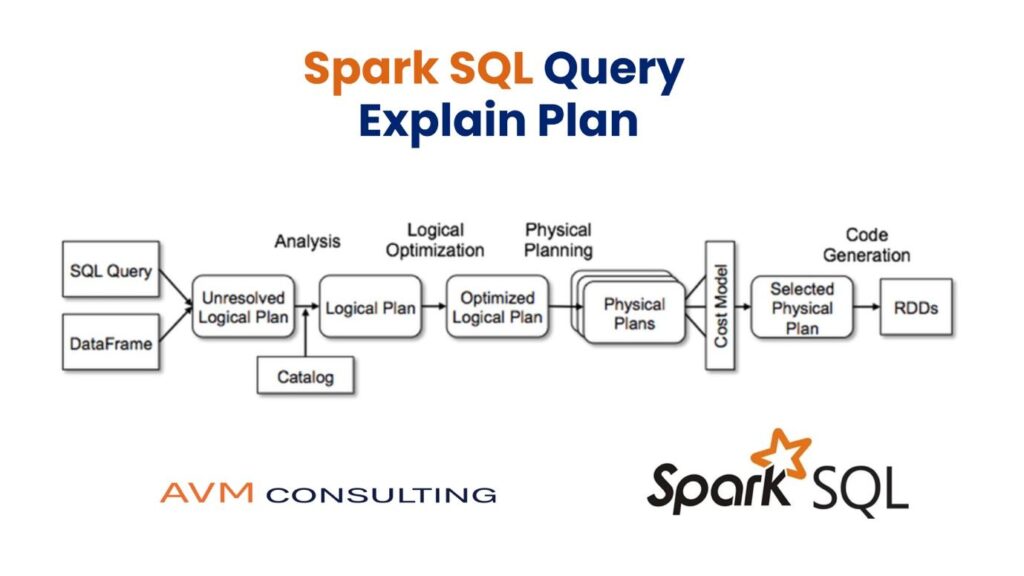
Spark SQL Query Explain Plan
DSE 5.0.6, Spark 1.6.2
Example 1
CREATE TABLE avm.transactions (
txn_status text,
txn_date date,
user_name text,
merchant_name text,
txn_amt int,
txn_id uuid,
txn_time timestamp,
PRIMARY KEY ((txn_status, txn_date), txn_time, txn_id) WITH CLUSTERING ORDER BY (txn_time DESC)
)
From cqlsh, below query works
cassandra@cqlsh:avm> select * from transactions where txn_status IN ('SUCCESS','FAILED') and txn_date IN
('2017-07-16', '2017-07-17') limit 10;
Below query does a Full Table Scan(FTS)
spark-sql>select * from transactions where txn_date IN (cast('2017-07-16' as date),cast('2017-07-17' as date))
and event_name in ('SUCCESS','FAILED') AND MERCHANT_NAME='merchant1' limit 10
Below query does not do FTS, because leading partition key column is txn_status
spark-sql>select * from transactions where txn_date IN (cast('2017-07-16' as date),cast('2017-07-17' as date)) and
txn_status= 'SUCCESS' AND MERCHANT_NAME='merchant1' limit 10
Below query does not return result at all if txn_date is not cast
spark-sql>select * from transactions where txn_date IN ('2017-07-16' '2017-07-17') and txn_status= 'SUCCESS'
AND MERCHANT_NAME='merchant1' limit 10
Example 2
CREATE TABLE avm.transactions_by_userid_month (
txn_status text,
txn_date date,
user_name text,
userid text,
merchant_name text,
txn_amt int,
txn_id uuid,
txn_month int,
PRIMARY KEY ((userid, txn_month), txn_date,txn_id) WITH CLUSTERING ORDER BY (txn_date DESC)
)
spark-sql> explain select txn_amt from avm.transactions_by_userid_month where userid='11111' and txn_month=201711;
== Physical Plan ==
Project [txn_amt#58L]
+- Scan org.apache.spark.sql.cassandra.CassandraSourceRelation@4ec1192f[txn_amt#58L] PushedFilters: [EqualTo(userid,11111), EqualTo(txn_month,201711)]
Time taken: 0.413 seconds, Fetched 3 row(s)
spark-sql> explain select txn_amt from avm.transactions_by_userid_month where userid='11111' and txn_month in (201711,201710);
== Physical Plan ==
Project [txn_am#58L]
+- Scan org.apache.spark.sql.cassandra.CassandraSourceRelation@4ec1192f[txn_am#58L] PushedFilters: [EqualTo(userid,11111), In(txn_month,[Ljava.lang.Object;@344db28d)]
Time taken: 0.685 seconds, Fetched 3 row(s)
Example 3
CREATE TABLE avm.transactions (
txn_status text,
txn_date date,
user_name text,
merchant_name text,
txn_amt int,
txn_id uuid,
txn_time timestamp,
PRIMARY KEY ((txn_status, txn_date), txn_time, txn_id) WITH CLUSTERING ORDER BY (txn_time DESC)
)
spark-sql> explain select user_name,merchant_name,txn_status,txn_amt from transactions where txn_date IN
(cast('2017-06-30' as date),cast('2017-07-15' as date)) and txn_status= 'SUCCESS' and
txn_time >= cast('2017-06-30' as timestamp) and txn_time <= cast('2017-07-15' as timestamp);
== Physical Plan ==
Project [user_name#12,merchant_name#13,txn_status#45,txn_amt#39]
+- Filter ((txn_time#14 >= 1498780800000000) && (txn_time#14 <= 1500076800000000))
+- Scan org.apache.spark.sql.cassandra.CassandraSourceRelation@3c12f87d[txn_time#14,txn_amt#39,user_name#12,merchant_name#13,txn_status#45] PushedFilters: [EqualTo(txn_status,SUCCESS), In(txn_date,[Ljava.lang.Object;@2de3ac17), GreaterThanOrEqual(txn_time,2017-06-30 00:00:00.0), LessThanOrEqual(txn_time,2017-07-15 00:00:00.0)]
Time taken: 0.555 seconds, Fetched 4 row(s)
spark-sql> explain select user_name,merchant_name,txn_status,txn_amt from transactions where txn_date =(cast('2017-06-30' as date)) and txn_status IN ('SUCCESS','FAILED') and txn_time >= cast('2017-06-30' as timestamp) and txn_time <= cast('2017-07-15' as timestamp);
== Physical Plan ==
Project [user_name#12,merchant_name#13,txn_status#45,txn_amt#39]
+- Filter (((txn_status#10 IN (SUCCESS,FAILED) && (txn_date#11 = 1498780800000000)) && (txn_time#14 >= 1498780800000000)) && (txn_time#14 <= 1500076800000000))
+- Scan org.apache.spark.sql.cassandra.CassandraSourceRelation@3c12f87d[txn_status#10,txn_time#14,txn_amt#39,user_name#12,merchant_name#13,txn_status#45,txn_date#11] PushedFilters: [In(txn_status,[Ljava.lang.Object;@4f1cb802), EqualTo(txn_date,2017-06-30), GreaterThanOrEqual(txn_time,2017-06-30 00:00:00.0), LessThanOrEqual(txn_time,2017-07-15 00:00:00.0)]
Example 4
spark-sql> explain select min(txn_time),max(txn_time) from transactions where txn_date ='2017-06-30' and txn_status='FAILED';
== Physical Plan ==
TungstenAggregate(key=[], functions=[(min(txn_time#38),mode=Final,isDistinct=false),(max(txn_time#38),mode=Final,isDistinct=false)], output=[_c0#45,_c1#46])
+- TungstenExchange SinglePartition, None
+- TungstenAggregate(key=[], functions=[(min(txn_time#38),mode=Partial,isDistinct=false),(max(txn_time#38),mode=Partial,isDistinct=false)], output=[min#51,max#52])
+- Project [txn_time#38]
+- Scan org.apache.spark.sql.cassandra.CassandraSourceRelation@bf2f2ce[txn_time#38] PushedFilters: [EqualTo(txn_date,2017-06-30), EqualTo(txn_status,FAILED)]
Time taken: 1.789 seconds, Fetched 6 row(s)
spark-sql> explain select min(txn_time),max(txn_time) from transactions where txn_date =cast('2017-06-30' as date) and txn_status='FAILED';
== Physical Plan ==
TungstenAggregate(key=[], functions=[(min(txn_time#38),mode=Final,isDistinct=false),(max(txn_time#38),mode=Final,isDistinct=false)], output=[_c0#54,_c1#55])
+- TungstenExchange SinglePartition, None
+- TungstenAggregate(key=[], functions=[(min(txn_time#38),mode=Partial,isDistinct=false),(max(txn_time#38),mode=Partial,isDistinct=false)], output=[min#60,max#61])
+- Project [txn_time#38]
+- Scan org.apache.spark.sql.cassandra.CassandraSourceRelation@bf2f2ce[txn_time#38] PushedFilters: [EqualTo(txn_date,2017-06-30), EqualTo(txn_status,FAILED)]
Time taken: 1.379 seconds, Fetched 6 row(s)
Example 5
CREATE TABLE avm.transactions_by_userid (
txn_status text,
txn_date date,
user_name text,
merchant_name text,
txn_amt int,
txn_id uuid,
txn_time timestamp,
PRIMARY KEY (userid, txn_time, txn_id) WITH CLUSTERING ORDER BY (txn_time DESC)
)
spark-sql> explain select userid,min(txn_time) first_txn_date from avm.transactions_by_userid group by userid;
== Physical Plan ==
TungstenAggregate(key=[userid#3], functions=[(min(txn_time#4),mode=Final,isDistinct=false)], output=[userid#3,first_txn_date#0])
+- TungstenExchange hashpartitioning(userid#3,200), None
+- TungstenAggregate(key=[userid#3], functions=[(min(txn_time#4),mode=Partial,isDistinct=false)], output=[userid#3,min#47])
+- Scan org.apache.spark.sql.cassandra.CassandraSourceRelation@6da76bb1[userid#3,txn_time#4]
Time taken: 3.655 seconds, Fetched 5 row(s)
CATEGORIES





More News



