September 24, 2017
Datastax Cassandra on AWS
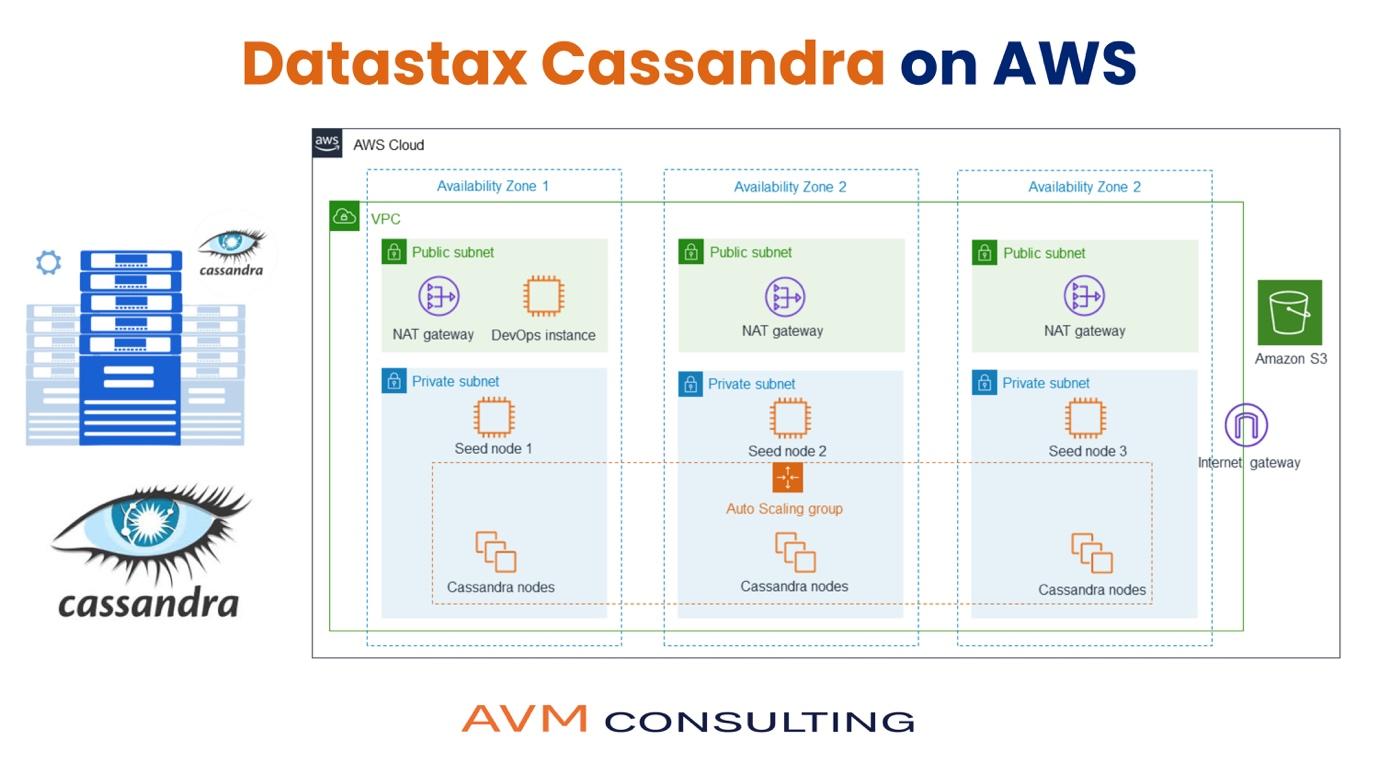
Setting up AWS EC2
Instance Type: m4.xlarge, 4 node cluster, 2 in each AZ
Storage: Two EBS volumes, data volume 400GB, 150GB log volume, root volume 150GB (General Purpose SSD)
OS:Amazon Linux AMI 2016.09.0 (HVM), SSD Volume Type – ami-b953f2da
The Amazon Linux AMI is an EBS-backed, AWS-supported image. The default image includes AWS command line tools, Python, Ruby, Perl, and Java. The repositories include Docker, PHP, MySQL, PostgreSQL, and other packages.
Root device type: ebs Virtualization type: hvm
File System:
xfs is not available in amazon linux, so using ext4
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 10G 0 disk
└─xvda1 202:1 0 10G 0 part /
xvdb 202:16 0 10G 0 disk
xvdc 202:32 0 50G 0 disk
$ sudo mkfs -t ext4 /dev/xvdc => data volume
$ sudo mkfs -t ext4 /dev/xvdb => log volume
$ sudo mkdir /dsedata /dselog
$ sudo mount /dev/xvdc /dsedata
$ sudo mount /dev/xvdb /dselog
$ sudo vi /etc/fstab
/dev/xvdc /dsedata ext4 defaults 0 2
/dev/xvdb /dselog ext4 defaults 0 2
Networking:
Setup a private subnet one each for one AZ for the cassandra nodes
2 ENIs for each of 2 seed nodes (one in each AZ)
Setup a NAT instance/NAT Gateway in public subnet for software download from internet
Setup bastion host for ssh access to cassandra nodes in a public subnet, one for each AZ
Setting up Cassandra
Pre-Requisites:
$ sudo useradd cassandra
$ cat /sys/class/block/xvdc/queue/scheduler
[noop]
$ cat /sys/class/block/xvdc/queue/rotational 0 $ cat /sys/class/block/xvdc/queue/read_ahead_kb 128 $ touch /var/lock/subsys/local $ echo 8 > /sys/class/block/xvdc/queue/read_ahead_kb $ echo 8 > /sys/class/block/xvdb/queue/read_ahead_kb /etc/sysctl.conf net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.core.rmem_default = 16777216 net.core.wmem_default = 16777216 net.core.optmem_max = 40960 net.ipv4.tcp_rmem = 4096 87380 16777216 net.ipv4.tcp_wmem = 4096 65536 16777216 vm.max_map_count = 1048575 $ sudo cat /sys/kernel/mm/transparent_hugepage/enabled always [madvise] never $ sudo cat /sys/kernel/mm/transparent_hugepage/defrag [always] madvise never $ sudo echo never | sudo tee /sys/kernel/mm/transparent_hugepage/defrag never $ sudo cat /sys/kernel/mm/transparent_hugepage/defrag always madvise [never] $ cat /proc/sys/vm/zone_reclaim_mode 0 /etc/pam.d/su session required pam_limits.so $ sudo yum install java-1.8.0 $ sudo yum remove java-1.7.0-openjdk $ sudo /usr/sbin/alternatives –config java $ java -version openjdk version “1.8.0_111” OpenJDK Runtime Environment (build 1.8.0_111-b15) OpenJDK 64-Bit Server VM (build 25.111-b15, mixed mode) $ sudo /usr/sbin/alternatives –config java There is 1 program that provides ‘java’. Selection Command ———————————————– *+ 1 /usr/lib/jvm/jre-1.8.0-openjdk.x86_64/bin/java Enter to keep the current selection[+], or type selection number: $ python Python 2.7.12 (default, Sep 1 2016, 22:14:00) [GCC 4.8.3 20140911 (Red Hat 4.8.3-9)] on linux2 Type “help”, “copyright”, “credits” or “license” for more information. $ chkconfig –list ntpd ntpd 0:off 1:off 2:on 3:on 4:on 5:on 6:off $ ps -fe | grep ntp /etc/security/limits.d/cassandra.conf cassandra – memlock unlimited cassandra – nofile 100000 cassandra – nproc 32768 cassandra – as unlimited sudo chown cassandra:cassandra /dsedata sudo chown cassandra:cassandra /dselog sudo chown cassandra:cassandra /dsedata/* sudo chown cassandra:cassandra /dselog/*
Installation:
$ curl --user <email_id>:<password> -O http://downloads.datastax.com/enterprise/DataStaxEnterprise-5.0.6-linux-x64-installer.run
$ chmod u+x DataStaxEnterprise-5.0.6-linux-x64-installer.run
$ sudo ./DataStaxEnterprise-5.0.6-linux-x64-installer.run --optionfile datastax-DC1-cassandra.prop --mode unattended
$ cat datastax-DC1-cassandra.prop | grep -v ^# | sed '/^$/d'
prefix=/usr/share/dse
system_install=services_and_utilities
update_system=1
cassandra_user=cassandra
cassandra_group=cassandra
start_services=1
ring_name=Cassandra_Cluster
run_pfc=1
pfc_fix_issues=1
/etc/dse/cassandra/cassandra.yaml
hints_directory: /dsedata/hints
authenticator: PasswordAuthenticator
authorizer: CassandraAuthorizer
role_manager: CassandraRoleManager
data_file_directories:
- /dsedata/data
commitlog_directory: /dselog/commitlog
saved_caches_directory: /dsedata/saved_caches
seed_provider:
- seeds: "172.31.12.201" (add one node in each AZ as seed, give ENI private IP)
listen_address: 172.31.12.201
rpc_address: 172.31.12.201
endpoint_snitch: Ec2Snitch
/etc/dse/cassandra/cassandra-rackdc.properties
dc_suffix=-_1_cassandra
prefer_local=true
/etc/default/dse
SPARK_ENABLED=1
/etc/dse/cassandra/cassandra-env.sh
MAX_HEAP_SIZE="5G"
cat .cassandra/cqlshrc
[connection]
request_timeout = 3600 cqlsh> ALTER KEYSPACE “system_auth” WITH REPLICATION = {‘class’ : ‘NetworkTopologyStrategy’, ‘ap-southeast_1_cassandra’ : 4}; cqlsh>alter KEYSPACE dse_leases WITH replication = {‘class’: ‘NetworkTopologyStrategy’, ‘ap-southeast_1_cassandra’: ‘3’}; cqlsh>create role admin with password=’******’ and superuser=true and login=true; cqlsh>ALTER ROLE cassandra WITH PASSWORD=’SomePasswordLikeThisIsBlocked’ and superuser=false; $ dsetool perf cqlslowlog enable
Verification:
$ sudo service dse start
Starting DSE daemon : dse
DSE daemon starting with only Cassandra enabled (edit /etc/default/dse to enable other features)
$ sudo service dse status
dse is running
$ cat /proc/16345/limits
Limit Soft Limit Hard Limit Units
Max cpu time unlimited unlimited seconds
Max file size unlimited unlimited bytes
Max data size unlimited unlimited bytes
Max stack size 8388608 unlimited bytes
Max core file size 0 unlimited bytes
Max resident set unlimited unlimited bytes
Max processes 32768 32768 processes
Max open files 100000 100000 files
Max locked memory unlimited unlimited bytes
Max address space unlimited unlimited bytes
Max file locks unlimited unlimited locks
Max pending signals 64118 64118 signals
Max msgqueue size 819200 819200 bytes
Max nice priority 0 0
Max realtime priority 0 0
Max realtime timeout unlimited unlimited us
$ dsetool ring
$ dsetool status
Cassandra on AWS – Some Best Practices:
- SSD is the recommended storage mechanism for Cassandra.
- The recommended file system for all volumes is XFS. Ext4 might be used by preference.
- Choose instance types with enhanced networking enabled. Enhanced networking offers better network performance.
- Insert heavy workloads are CPU-bound in Cassandra before becoming IO-bound.
- With Amazon EC2 for write-heavy workloads, you should look at instance types with at least 4 vCPUs.
- If you are just starting out with Cassandra, plan for cluster growth from the beginning.
- Choose Ec2MultiRegionSnitch to avoid complications when you decide to expand your cluster.
- We highly recommend that you spread your seed nodes across multiple Availability Zones.
- Attach an ENI to each seed node and add the ENI IP address to the list of seed nodes in the .yaml configuration file.
- Multiple EBS volumes for data and one separate ebs volume for commit log.
- Amazon EBS also provides a feature for backing up the data on your EBS volumes to Amazon S3 by taking point-in-time snapshots.
- Setup Autoscaling and automation scripts – Autoscaling groups (seed, non seed)
- Setup Bastion Host
- HA for OpsCenter and separate autoscaling group for it
- Custom AMI with Cassandra package is also available
- Netflix-built and open-sourced tool Priam or tablesnap for backups
- We should go for M4 series, since we are not using ephemeral disks that come with M3, so 10$ per server reduced cost