May 28, 2019
How to create a simple Cassandra Cluster on AWS

What is Cassandra?
Apache Cassandra is a free and open-source distributed wide column store NoSQL database management system designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. Wikipedia
Apache Cassandra is a high performance, extremely scalable, fault tolerant (i.e. no single point of failure), distributed post-relational database solution. Cassandra combines all the benefits of Google Bigtable and Amazon Dynamo to handle the types of database management needs that traditional RDBMS vendors cannot support. (Source: DataStax).
Why do we even need to self manage and run Apache Cassandra if we have Amazon Managed DynamoDB?
Cassandra and DynamoDB both origin from the same paper: Dynamo: Amazon’s Highly Available Key-value store. (By the way — it has been a very influential paper and set the foundations for several NoSQL databases).
Of course it means that DynamoDB and Cassandra have a lot in common! (They have the same DNA). However both AWS DynamoDB and Apache Cassandra have evolved quite a lot since this paper was written back in 2007 and there are now some key differences to be aware of when choosing between the two.
Both databases have their own advantages and disadvantages, you can choose the one that best matches your requirements. Read here in detail.
We were initially using DynamoDB. Our primary reason to switch from DynamoDB to Cassandra was Total Cost of Ownership (TCO).
We have been able to reduce the cost to almost half what we were paying for DynamoDB.
Other benefits are: Cassandra is Open Source, it provides full active-active multi-region support, significantly lower latency than DynamoDB, etc.
Read detailed comparison over TCO of DynamoDB and Cassandra here.
Bootstrap the cluster:

We are currently using 3 node cluster and host OS is Ubuntu running on AWS EC2.
Step 1: Launch 3 Ubuntu based instances in 3 different AZs.
Step 2: Update, Upgrade and Restart the instances
$ sudo apt update \
$ sudo apt upgrade -y
You may need to reboot instance.
Step 3: Add the Apache repository of Cassandra to /etc/apt/sources.list.d/cassandra.sources.list.
$ sudo echo “deb http://www.apache.org/dist/cassandra/debian 311x main” | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
Step 4: Add the Apache Cassandra repository keys:
$ sudo curl https://www.apache.org/dist/cassandra/KEYS | sudo apt-key add -
Step 5: Update the repositories:
$ sudo apt update
Step 6: Install Cassandra
$ sudo apt install cassandra
Step 7: Stop Cassandra Service
$ sudo service cassandra stop
Steps 1–7 ensure that all the instances are up to date and have Cassandra installed on it.
Now in order to create a Cluster of these 3 nodes or add a new node to existing cluster, follow above 1–7 steps and then below steps:
Step 1: Goto Cassandra Conf Directory.
$ cd /etc/cassandra
Step 2: Take backup of main configuration file before you make any change in it.
$ sudo cp cassandra.yaml cassandra.yaml.bak
Step 3: Open cassandra.yaml in your favorite editor and edit below parameters as mentioned below:
cluster_name: ‘My Cluster’
authenticator: PasswordAuthenticator (optional)
seeds: “node_private_ip_address”
listen_address:<node_private_ip_address>
rpc_address: 0.0.0.0
broadcast_rpc_address:<node_private_ip_address>
endpoint_snitch: Ec2Snitch
Step 4: Save the cassandra.yaml file.
Step 5: Clear the default data from the Cassandra system table in order to import the new values set in the cassandra.yaml config file:
$ sudo rm -rf /var/lib/cassandra/data/system/*
Step 6: Start Cassandra Service on that node.
$ sudo service cassandra start
Step 7: Wait for 10 second and check cluster status.
$ sudo nodetool status
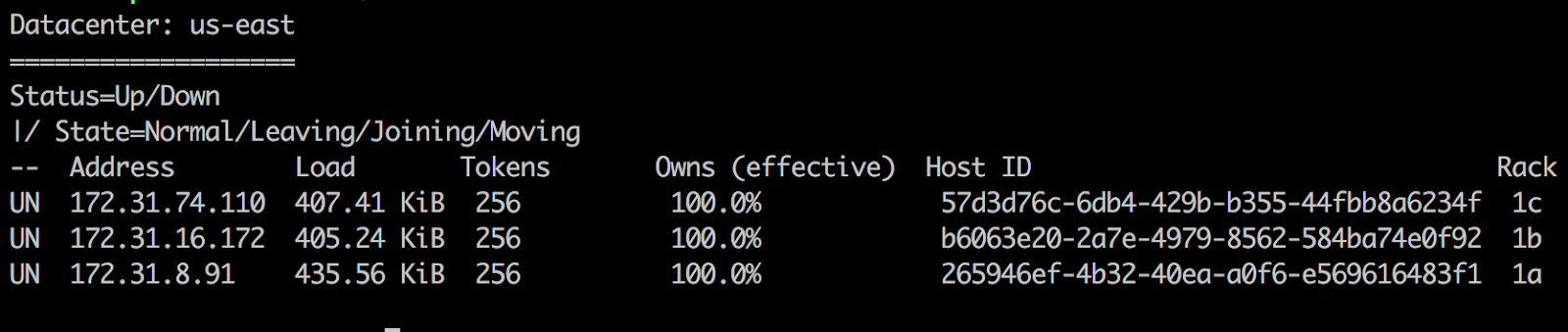
Result something like above will appear. If new node is in Joining state, you will see UJ in the beginning of that node.
Step 8: After all new nodes are running, run nodetool cleanup on each of the previously existing nodes to remove the keys that no longer belong to those nodes. Wait for cleanup to complete on one node before running nodetool cleanup on the next node. Cleanup can be safely postponed for low-usage hours.
Note: Do not use new node as Seed Node, once a node is a part of Cluster, it can be promoted as Seed Node. Maximum 3 should in a cluster should be fine. Do not make all nodes seed nodes.
Important point : For a Cassandra cluster running on AWS, we use Ec2Snitch in single region cluster and Ec2MultiRegionSnitch in multi-region cluster as name suggests. Know more about Cassandra Snitch Classes here.
It’s a fairly simple cluster to get started with, there is lots of scope of improvements.
Thanks for reading. Happy Cloud Computing 🙂





More News



