June 3, 2012
Index Clustering factor. One way how to avoid negative performance impact on joins which involves bad clustered indexes.
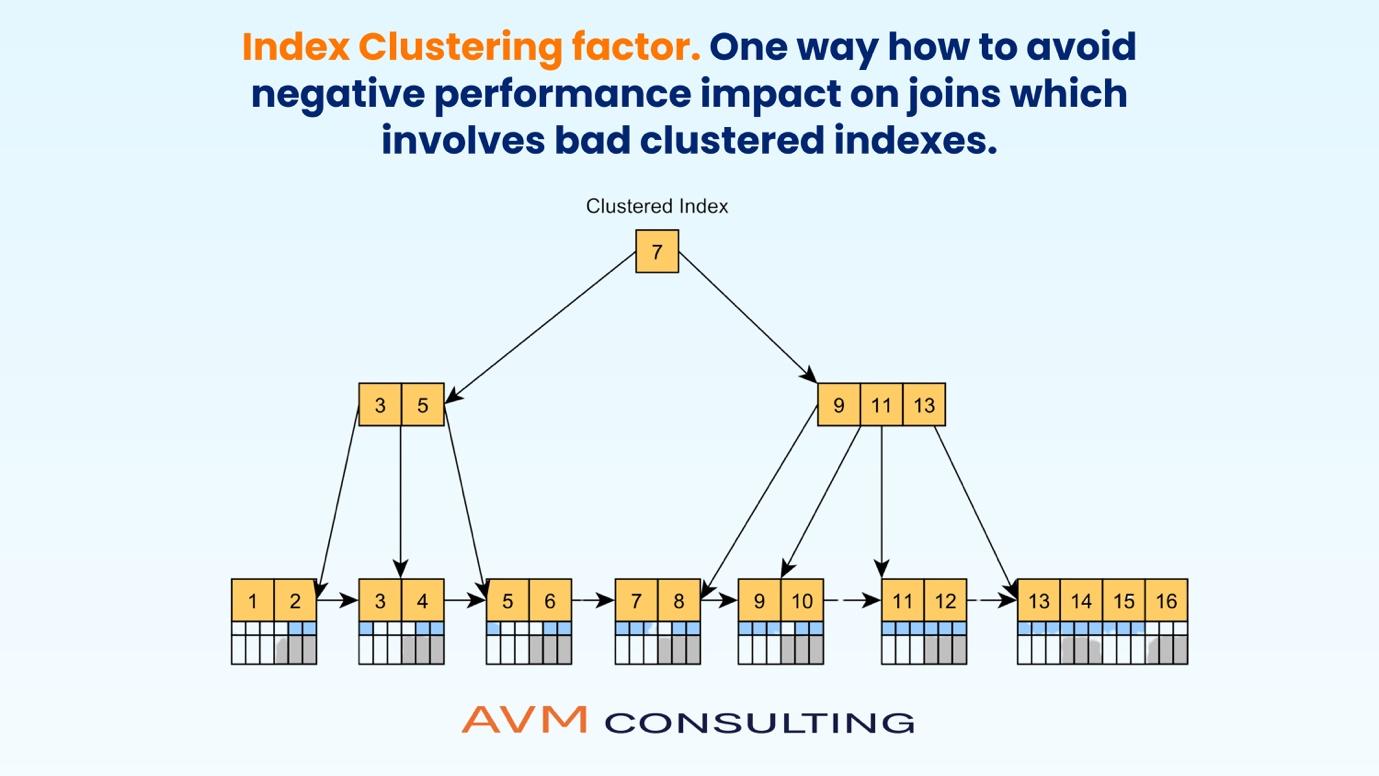
High Index Clustering factor is popular problem in SQL world.
The most known solution for it – rebuild table ordering by columns what are in the index.
But in real world, with table size growing exponentially its not always practical or possible to do it.
Here is one way to avoid index clustering problem by SQL optimization..
Consider classical example.
We have tables:
1. customer
CREATE TABLE customer
(customer_id NUMBER,
name VARCHAR2(50),
dob DATE,
status VARCHAR2(20),
...
CONSTRAINT customer_pk PRIMARY KEY (customer_id)
); 2. service_provider
CREATE TABLE service_provider
(service_provider_id NUMBER,
name VARCHAR2(100),
street_address VARCHAR2(100),
status VARCHAR2(20),
...
CONSTRAINT service_provider_pk PRIMARY KEY (service_provider_id)
); 3. feedback
CREATE TABLE feedback
(service_provider_id NUMBER,
customer_id NUMBER,
score NUMBER,
...
);
CREATE INDEX fdb_serv_provr_cust_scr ON feedback (service_provider_id,customer_id);
CREATE INDEX fdb_cust_serv_provr_scr ON feedback (customer_id,service_provider_id); Table size is important here, so lets say CUSTOMER and SERVICE_PROVIDER are in millions of rows, with table segments in range 5-30 GBs.
FEEDBACK is intersection table, it’s size is in multi TBs, and row count in 100s of billions. Very Large table.
The tables can be either partitioned or not, but for simplicity of example lest assume they are not.
Now – classical SQL. The SQL execution frequency is high:
select * from service_provider s, feedback f
where f.customer_id=:1
and f.service_provider_id=s.service_provider_id
and s.status='ACTIVE'
Oracle gives following execution plan for the SQL (at time of writing, tested on all major versions from 10.2.0.1 to 11.2.0.3):
Execution Plan
----------------------------------------------------------
Plan hash value: 2452536980
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 143 | 621 (1)| 00:04:05 |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 1 | 143 | 611 (1)| 00:04:05 |
| 3 | TABLE ACCESS BY INDEX ROWID| FEEDBACK | 300 | 527K| 310 (1)| 00:02:05 |
|* 4 | INDEX RANGE SCAN | FDB_CUST_SERV_PROVR_SCR | 300 | | 62 (0)| 00:00:01 |
|* 5 | INDEX UNIQUE SCAN | SERVICE_PROVIDER_PK | 1 | | 1 (0)| 00:00:01 |
|* 6 | TABLE ACCESS BY INDEX ROWID | SERVICE_PROVIDER | 1 | 89 | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("F"."CUSTOMER_ID"=:1)
5 - access("F"."SERVICE_PROVIDER_ID"="S"."SERVICE_PROVIDER_ID")
6 - filter("S"."STATUS"='ACTIVE')
And this plan if given regardless of selectivity of condition “s.status=’ACTIVE'”:
If its only 1% of row set in the query meet condition “s.status=’ACTIVE'”, or 90% – Oracle does not change the plan.
But what happens if selectivity is high and “s.status=’ACTIVE’” filters out a lot of data from the select?
Here would be execution steps:
Step 1.
(from plan above related to id=3)
Oracle will read index FDB_CUST_SERV_PROVR_SCR doing INDEX RANGE SCAN on condition “4 – access(“F”.”CUSTOMER_ID”=:1)”. With standard DB block size 8k, and lets assume customer having 300 feedbacks, it will result in 1-2 index leaf block reads and 3-4 total I/Os on the index. Index FDB_CUST_SERV_PROVR_SCR is large, so in the worst case scenario it can be all physical I/O. Assuming underling storage is RAID 10 FC disks, average Random read is 10ms. This step will take about 4*10=40 ms.
So as a result of the step 300 CUSTOMER_ID-SERVICE_PROVIDER_ID-ROWID sets will be available.
Step 2.
(from plan above related to id=4)
Now using 300 ROWIDs from step 1, rows from FEEDBACK table will be located. Assuming the index have below average clustering factor, and table is huge, it will be safe assumption to say almost each row will be in different table block. With FEEDBACK been large table, almost all I/O will be physical. It will be 300 random single block read physical I/Os.
So we are talking about – 10ms*300=3 seconds. For this step only.
As a result of the step 300 rows from FEEDBACK table will be available. They are needed for final result (“select *” was used).
Step 3.
(from plan above related to id=5)
using SERVICE_PROVIDER_ID from step 1 as an input for “INDEX UNIQUE SCAN” on SERVICE_PROVIDER_PK it will be one index lookup. With most probable index depth of 3 it will be 3 I/O operation. BUT 99% chance it will be logical I/O, as SQL is executed often and index SERVICE_PROVIDER_PK on several millions record table will be in lower GBs (in my case 1Gb). So we are talking about (will take average memory access time 50ns) 50ns*3=0.00015ms. With 1% chance on physical I/O: (10ms*1+0.00015ms*99)/100=0.1 ms.
As a result of the step one ROWID for SERVICE_PROVIDER table will be available.
Step 4.
(from plan above related to id=6)
Using one ROWID from step 3 it will be one “TABLE ACCESS BY INDEX ROWID” to SERVICE_PROVIDER. But again, with SERVICE_PROVIDER been in lower GBs, and SQL been called often most of I/O will be logical.
With 1% chance of physical I/O this step will take (99*0.00005ms+1*10ms)/100=0.1 ms As a result of the step, one row for SERVICE_PROVIDER table will be available for final output (“select *” was used).
So far, step 2 is heaviest/longest by far.
Step 5.
(from plan above related to id=6)
Now when row from SERVICE_PROVIDER is available “filter(“S”.”STATUS”=’ACTIVE’)” comes to the picture. As was mentioned above it very selective, lets say 90%. And so it means what we do not need 90% of rows what was selected from FEEDBACK table on step 2. And 90% of time spent in step 2 was waste of DBtime.
Steps 3-5 will repeat 300 times. Even after repeating steps 3-5 300 times, step 2 is still heaviest by far.
What if we touch table FEEDBACK when we really need it? Meaning after filter(“S”.”STATUS”=’ACTIVE’) throw out 90% of not-needed data.
We can save 90% of physical I/O and so – time, on step 2.
Physically this is very possible as we have SERVICE_PROVIDER_ID in “step 1”. So we can easily use the SERVICE_PROVIDER_ID to lookup SERVICE_PROVIDER via SERVICE_PROVIDER_PK, then run filter “filter(“S”.”STATUS”=’ACTIVE’)” and in very end, only if filter was positive, – lookup record in FEEDBACK table by ROWID what we already got from “step 1”.
What I am trying to achieve would express in following plan:
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 163 | 303 (1)| 00:02:02 |
| 1 | NESTED LOOPS | | 1 | 163 | 303 (1)| 00:02:02 |
| 2 | NESTED LOOPS | | 1 | 109 | 302 (1)| 00:02:02 |
|* 3 | INDEX RANGE SCAN | FDB_CUST_SERV_PROVR_SCR | 300 | 195K| 62 (0)| 00:00:01 |
|* 4 | TABLE ACCESS BY INDEX ROWID| SERVICE_PROVIDER | 1 | 89 | 2 (0)| 00:00:01 |
|* 5 | INDEX UNIQUE SCAN | SERVICE_PROVIDER_PK | 1 | | 1 (0)| 00:00:01 |
| 6 | TABLE ACCESS BY USER ROWID | FEEDBACK | 1 | 54 | 1 (0)| 00:00:01 |<<---Get records from FEEDBACK after running "filter("S"."STATUS"='ACTIVE')"
----------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("F"."CUSTOMER_ID"=:1)
4 - filter("S"."STATUS"='ACTIVE')
5 - access("F"."SERVICE_PROVIDER_ID"="S"."SERVICE_PROVIDER_ID")
I was not able to find any way to hint SQL, to adjust it to plan like this (if anybody knows the way it would be cool).
But with some regrouping its possible. This SQL will produce the plan above (looks nasty but works well):
select q2.*, q1.* from
(
select f.rowid ri, s.* from feedback f, service_provider s
where f.customer_id=:1
and f.service_provider_id=s.service_provider_id
and s.status='ACTIVE'
) q1,
feedback q2
where q1.ri=q2.rowid;
In some cases it worked for me just as shown above, in some different data distributions and/or optimizer versions I had to put couple hints:
select /*+ no_merge ordered */ q2.*, q1.* from
(
select f.rowid ri, s.* from feedback f, service_provider s
where f.customer_id=:1
and f.service_provider_id=s.service_provider_id
and s.status='ACTIVE'
) q1,
feedback q2
where q1.ri=q2.rowid;
And also.. – this technique does not work for optimizer after 11.2.0.1. When I would have more time for this, I will trace the SQL with 10053 event on 11.2 version and figure out why..(I promise ). But before that setting optimizer_features_enable to 11.1.0.7 would make a trick:
alter session set optimizer_features_enable='11.1.0.7';
Couple findings on sql plan:
- CBO did agree – its cheaper to access table FEEDBACK in in the end.
- CBO weighted “TABLE ACCESS BY INDEX ROWID” for FEEDBACK almost same as NL on SERVICE_PROVIDER. This will not be true, if the SQL frequency is high, and FEEDBACK is much bigger. But to be fair, CBO cant take frequency in consideration.
The best performance measurement of purely index based queries like this I think would be DBtime/row, what would be almost linear to physical I/O row.
To compare apples-to-apples this is what I used to see performance before and after optimization:
select st.sql_id, st.instance_number,
st.EXECUTIONS_DELTA,
st.BUFFER_GETS_DELTA /st.ROWS_PROCESSED_DELTA "logical IO per row",
st.DISK_READS_DELTA /st.ROWS_PROCESSED_DELTA "phisical IOs per row",
st.IOWAIT_DELTA /st.ROWS_PROCESSED_DELTA "time spent in IO (seconds/row)",
st.ELAPSED_TIME_DELTA/st.ROWS_PROCESSED_DELTA "total time spent (seconds/row)"
from DBA_HIST_SQLSTAT st, dba_hist_snapshot s
where
st.sql_id='&sql_id1'
and st.instance_number=s.instance_number
and s.BEGIN_INTERVAL_TIME between '&1' and '&2'
and s.snap_id=st.snap_id
and st.ROWS_PROCESSED_DELTA!=0
order by s.snap_id desc, instance_number;
Here are numbers from busiest production system I implement this technique to (one 30 minutes interval with old and new SQL):
SQL_ID EXECUTIONS_DELTA logical IO per row phisical IOs per row time spent in IO (ms/row) total time spent (ms/row)
------------- ---------------- -------------------- ----------------------- ---------------------------- --------------------------
old_sql 26219 72 8.11 50.11 57.1
new_sql 28936 71 0.91 5.900 6.10
As you can see Logical I/O is not much better in optimised query, as “step 3” contribute the most into logical I/O, and we did not optimise anything in step 3.
But physical I/O and total DB time improved almost 10 times.
The argument what would cross everything said above over – it would be same effect if we rebuild FEEDBACK table and improve FDB_CUST_SERV_PROVR_SCR clustering factor.
Yes true, but couple things
- Rebuilding on regular basis table what is TBs in size will be a interesting challenge if availability is important.
- What if there is a need to access FEEDBACK table by different index/dimension? For example:
select * from customer c, feedback f
where f.service_provider_id=:1
and f.customer_id=c.customer_id
and c.status='ACTIVE';
Adjusting FEEDBACK table to
FDB_CUST_SERV_PROVR_SCR(customer_id,service_provider_id)
index clustering would mess-up clustering on
FDB_SERV_PROVR_CUST_SCR(service_provider_id,customer_id) index.
And its only 2 dimensions in this example, it could be more.
Same time, this optimization would work regardless of clustering factor on any of them, as long as WHERE clause on table on the right is selective (“status=’ACTIVE’” in this example).
For cases where this optimization is applicable, it can also resolve data archival problem. – If data archival is needed for performance purposes, and not to safe on storage, this will make it. The query performance will be unchanged whether FEEDBACK table be 1TB or 100TB.
Simple making status=’INACTIVE’ on CUSTOMER and SERVICE_PROVIDER would be an archival.
No big data movement required.
I used for example here “CUSTOMER – FEEDBACK – SERVICE_PROVIDER” but idea of “intersection” table exists in almost any business model:
“PRODUCT – COMPATIBILITY – PRODUCT”
“MALE – MATCH – FEMALE”
“STUDENT – EXAM – EXAMINER”
“MERCHANT – TRANSACTION – BANK”
and so on.
In this example query is simplified to the limit, but does not mean it has to be that primitive.
To generalize, – this approach would work when:
There is query what join at least 2 tables. The table what is entry point (first step) for the query is very large and has index on at least 2 columns: fist column – entry condition on the query, second column – column what is foreign key (no constraint required) on second table in the query. And this query has where predicate on second table what is very selective. Second table is not too large. Query execution frequency is high.





More News



